Pac-Man AI
search · minimax · Q-learning agents
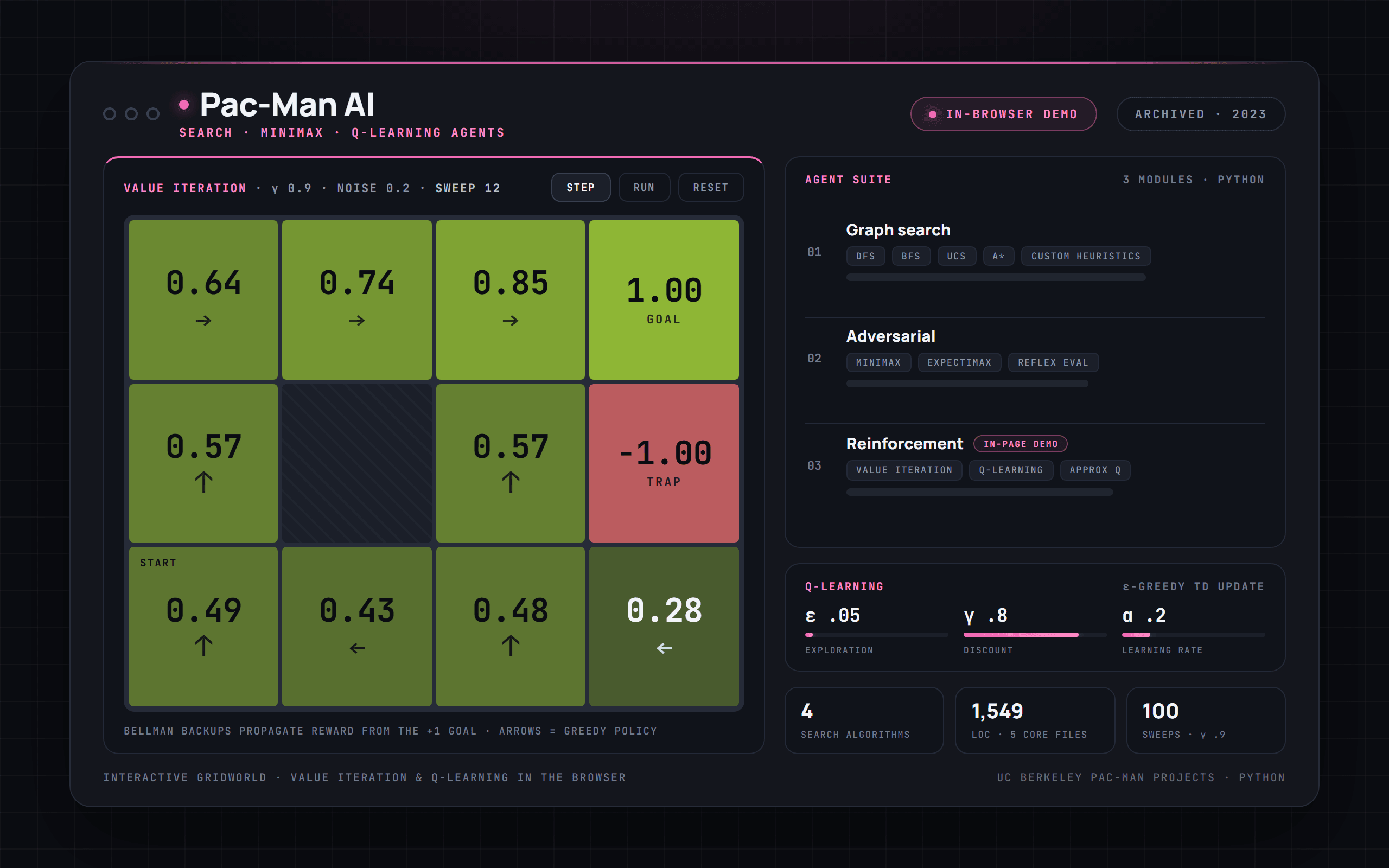
Bellman backups propagate reward outward from the +1 goal; the arrows are the greedy policy under the current values, the same MDP solve the project runs.
Interactive Gridworld: watch value iteration and Q-learning converge in your browser.
Implements the agent logic for the UC Berkeley Pac-Man projects across three modules. Search: depth-first, breadth-first, uniform-cost and A* graph search, plus a CornersProblem state representation with admissible corners/food heuristics to route Pac-Man through mazes optimally. Adversarial: a reflex evaluation function, a recursive multi-agent minimax agent, an expectimax agent (ghosts modeled as uniform-random), and a hand-tuned evaluation weighing food/ghost distance, scared timers and remaining pellets. Reinforcement learning: a value-iteration agent that solves known MDPs by Bellman sweeps over Gridworld, a tabular Q-learning agent (ε-greedy with α/γ temporal-difference updates), and an approximate Q-learning agent using linear function approximation over feature vectors, plus discount/noise/living-reward analysis for target policies. The in-page demo brings the Gridworld value-iteration / Q-learning loop into the browser.
- Python
- Search (DFS/BFS/UCS/A*)
- Minimax
- Expectimax
- MDPs
- Value Iteration
- Q-Learning
- Search algorithms
- 4 (DFS/BFS/UCS/A*)
- Agent code
- 1,549 LOC (5 core files)
- Q-learning
- ε .05 · γ .8 · α .2
- Value iteration
- γ .9 · 100 sweeps