
KickCast Calibration Study
isotonic recalibration · 2022 WC holdout
Closes KickCast's stated next step with measured results: on the 64-match 2022 World Cup holdout, isotonic recalibration cuts log-loss from 1.347 to 1.093 and 10-bin ECE from 0.157 to 0.120, documented with before/after reliability diagrams.
No runtime to launch: the deliverables are the study artifacts. Before/after reliability diagrams (10 bins, with bin counts) and the metrics on this page are computed from the saved KickCast model's real predictions on the 2022 World Cup holdout.
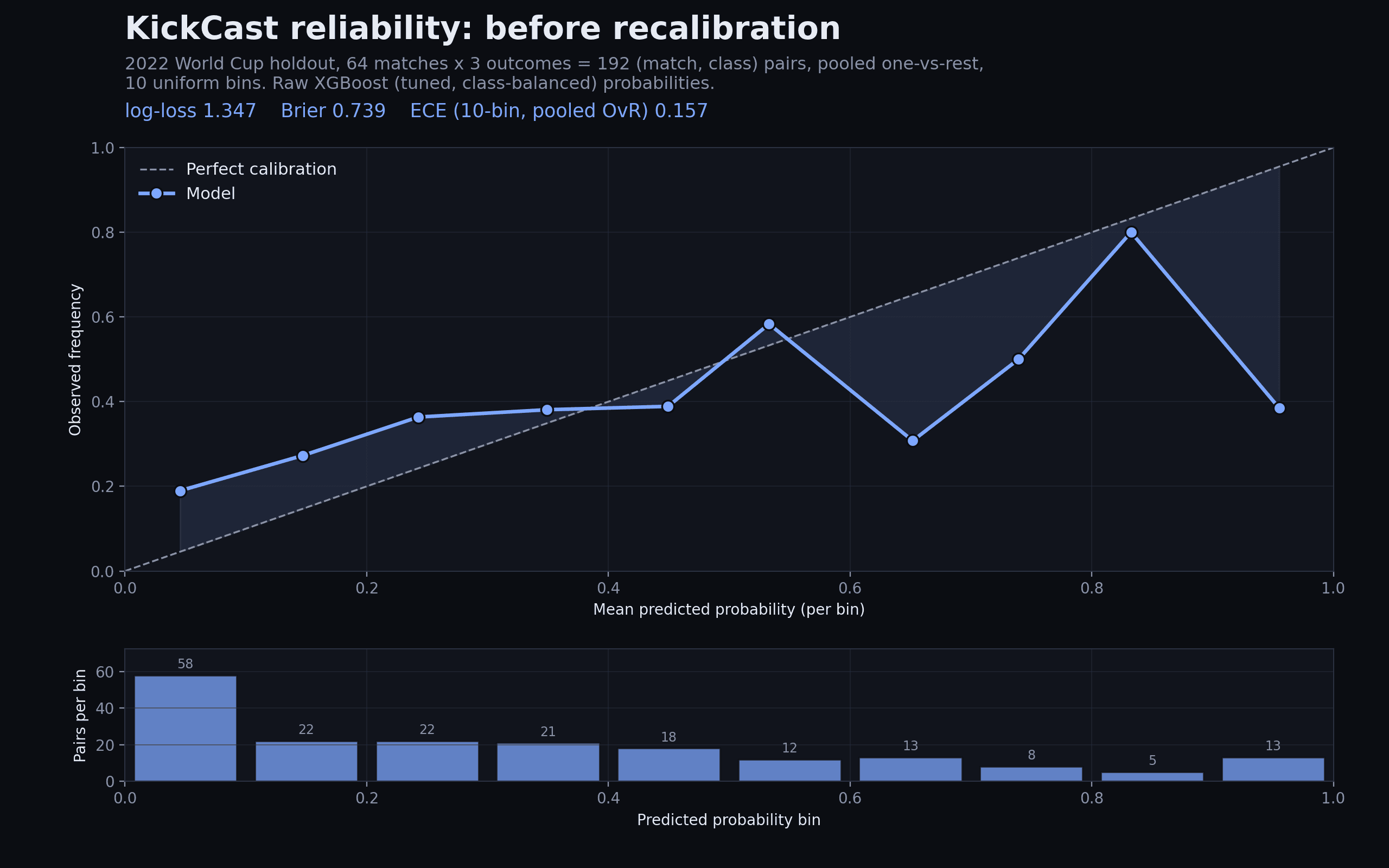
KickCast's honest self-review said the lever is calibration, not top-1 accuracy. This study completes that work on the real model and the real holdout. The saved tuned, class-balanced XGBoost artifact was loaded and first verified to reproduce the project's published test metrics exactly (log-loss 1.0308, accuracy 56.25% on the 3,552-match test split), then scored on the 64 matches of the 2022 World Cup, a holdout never touched during training or tuning. Reliability is measured as pooled one-vs-rest over 192 match-class pairs in 10 uniform bins: before recalibration the model shows ECE 0.157, log-loss 1.347 and multiclass Brier 0.739, under-confident at low probabilities and over-confident above 0.6. A per-class isotonic regression (with row renormalization) was then fit only on the chronologically earlier 2,324-match validation split (2020 to Nov 2022), so the holdout stayed unseen during fitting. After recalibration the same 64 matches score ECE 0.120, log-loss 1.093 and Brier 0.646; top-label ECE falls from 0.247 to 0.148 and top-1 accuracy moves from 45.3% to 50.0%. Caveat stated plainly: n=64 is a small sample, so per-bin points are noisy and the deltas carry wide uncertainty. As a robustness check the same calibrator was applied to the full 3,552-match test split, where log-loss drops from 1.031 to 0.923 and pooled ECE from 0.098 to 0.017, confirming the correction generalizes beyond the 64-match story.
- Python
- scikit-learn
- XGBoost
- Isotonic regression
- matplotlib
Architecture · saved model → measured calibration
Artifact fidelity check
Load the saved tuned, class-balanced XGBoost and verify it reproduces the published test metrics exactly (log-loss 1.0308, accuracy 56.25%, n=3,552) before trusting any new number.
Holdout scoring
Predict the 64 matches of the 2022 World Cup, a chronological holdout never used for training or tuning, and keep full 3-class probabilities per match.
Measure miscalibration
Reliability over 192 pooled one-vs-rest pairs, 10 uniform bins with bin counts: ECE 0.157, log-loss 1.347, Brier 0.739 before any correction.
Isotonic recalibration
Per-class isotonic regression, row-renormalized, fit only on the 2,324-match validation split (2020 to Nov 2022) so the holdout stays unseen.
Re-evaluate + robustness
Holdout after: ECE 0.120, log-loss 1.093, Brier 0.646 (n=64, noisy bins disclosed). Full test split: log-loss 1.031 → 0.923, ECE 0.098 → 0.017.
- ECE, 10-bin OvR (n=64)
- 0.157 → 0.120
- Log-loss (n=64)
- 1.347 → 1.093
- Brier, multiclass (n=64)
- 0.739 → 0.646
- Full-test ECE (n=3,552)
- 0.098 → 0.017

What I'd improve
The bootstrap CIs are now done (B=10,000, calibrator held fixed across resamples), and they sharpen the honest story: on the n=64 holdout the log-loss delta is -0.253 (95% CI [-0.421, -0.101]) and the Brier delta -0.093 (CI [-0.151, -0.036]), both excluding zero, but the ECE delta of -0.041 (CI [-0.101, +0.026]) crosses zero, so the holdout alone cannot certify the calibration gain. That is exactly why the full-test robustness check (n=3,552, ECE 0.098 to 0.017) carries the calibration claim. Still open: a head-to-head against temperature scaling and Dirichlet calibration, feeding the calibrated probabilities back into the 10,000-run Monte-Carlo simulation to measure how tournament odds shift, and backtesting across the 2010, 2014 and 2018 cycles.